作者Dr.2,MediCool医库软件公司董事长
随着计算机技术的发展,人机交互的方式也在不断变革,智能语音的发展更是为我们的生活及工作方式带来了新的变革,其每一步创新都带给我们更好的用户体验和更高的交互效率。语音识别即通过麦克风捕捉用户发出的声音,将声波信号转换成机器可以处理的“发音特征”,再从发音和语言的“模型空间”中快速搜索最匹配的句子,即识别结果。
基于语音识别的原理:语音识别过程就是一个模型匹配的过程,模型训练的好坏直接关系到系统识别的结果,图为语音识别模型匹配的过程:
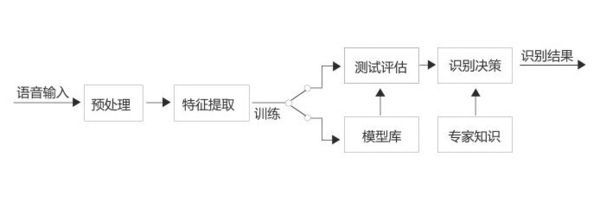
为了得到一个好的模型,往往需要有大量的原始语音数据来训练这个语音模型,特别是对于非特定人的语音识别系统来说,这一点显得更为重要。因此,在开始进行语音识别研究之前,首先要建立一个语音数据库,数据库包括不同性别、年龄、口音的说话人的声音,并且必须具有代表性,能均衡地反映实际使用情况。模型训练就是指按照一定的准则,从大量已知模式中获取表征该模式本质特征的模型参数。
目前在医学领域并没有专门的语音识别词库和模型,由于医学术语、药物名称、疾病名称等用词的专业性很强,因此识别率会大幅下降。Dr.2同学带了一个小组的人,耗费了7个月的时间,分别于IOS平台和Android平台,采用科大讯飞和云之声两个主流第三方SDK,对药品词库的36176个药品名称和疾病词库的23501个疾病名进行了测试,训练出错率较高的词汇,初步搭建了医学语音识别领域的第三方素材库,并决定免费开放给任何有志于开发移动医疗APP 的创业团队和个人。共同构建医学语音识别体系,避免重复投资,减少整个社会的资源浪费。
下面以Android为例,具体介绍我们构建体系的流程、标准和测试方法。以下方法可以帮助各位移动医疗开发人员快速上手:
测试平台:2台android4.0系统手机(小米2、中兴U930HD)、珍立拍系统、科大讯飞SDK
小 组: A组和B组
测试方法:对所有药品和疾病名称进行反复测试,使用纠正训练法,来克服语音识别体系中HMM的训练效果。小组A测试药品,小组B测试疾病,普通话识别。
测试步骤:
1、医学词汇约有数十万条,前期总结查找筛选最常用词汇并分组。
2、使用珍立拍系统中的语音识别对所有词库进行第一遍测试。
3、在第一遍测试的基础上,对筛选出来错误的词汇进行二次测试,再次筛选。
4、总结出识别易错词汇,两组交叉测试后,随后交给程序人员,按科大讯飞SDK模型训练,输入相应代码,完善建库。
测试统计结果:
可能存在的影响因素:
1、读错:由于医学词汇中有很多较为生僻的汉字,读错很难避免,很多医生即使会写这个词,但是发音也可能会错。
规避方法:遇到拿捏不准的汉字时,查找准确读音,尽量避免错误。
2、环境因素:测试时,所处的环境存在噪音。
规避方法:选择在低噪音环境中测试,但不能完全于安静的环境中测试,因其与日常使用环境不符。
3、汉字的同音字:例如:弱视、荨麻疹,识别结果:若是、寻麻疹。
4、汉字尾音:例如:肝癌,识别结果:刚来。
5、实际发音影响:例如:阻生齿,识别结果:主生殖。
下面以疾病词汇举例:
测试小结:
由统计结果可以看出疾病名的识别率高于药品名,笔者分析,造成此结果的原因是:疾病名的广普率要高于药品名,所以各个语音识别公司比较重视,而且疾病生僻汉字较少,而药品种类要远多于疾病种类,其中生僻汉字也较多。二次测试的正确率较一次测试大约提升了一个百分点左右,还是可以适当减少错误数据库中的词汇量。
音节短的词出错率较高,如:单音节词,痣(识别结果:志),双音节词,义眼(识别结果:一眼),长音节词出错率低,原因可能是音节越短的词,其同音节的普通词较其更常见,而且如果其尾音特殊的话,影响较大。
讨论:
针对医学专业词汇识别率低的问题,目前可使用以下三种解决办法:
一、 扩充自定义词库
虽然有用户词表,但是目前科大讯飞用户词表仅限数量2000,经沟通后他们正在扩大词汇表数量中。但如果数据过大,将会导致数据包过重的问题,而移动端由于存储和运算能力受限,所以无法满足数量庞大的整个医学词库,因此我们只能先做常用库。
二、 搭建第三方素材库
语音识别虽然在实用性上已得到很大提高,但是由于目前语音识别的单一性(只能单纯的识别中文或者英文),以及使用环境、语音差异化等因素的影响,容易造成识别错误。就这些因素而言,我们为此做了大量的基础工作,用于搭建第三方数据库,在尽可能排除其它干扰因素的情况下,检测出识别错误的词汇,也为下一步构建专业领域的识别模型搭建出了样本数据库(针对大量样本数据库,精简出识别错误的小样本数据库,减少模型训练词库)。
三、 构建专业领域的识别模型
对于有大量专业词汇的识别系统来说,使用模型训练可以有效提升识别率,目前模型训练比较常用的有四种方法:最大似然估计、纠正训练法、最小分类错误、最大互信息方法。模型训练需要专业的技术,并与语音识别公司进行合作,由企业提供词库信息和语音集,专业人员采用模型训练对需要识别的词库进行训练,最终给出个性化定制的识别模型,以提升识别率。
语音识别技术在移动医疗领域中的应用会越来越普遍,但还有大量的基础工作需要我们大家齐心协力去完成,Dr.2衷心希望业内的精英之士能够对此多交流,多合作,抛开一些利益的纠葛,共同为行业的发展贡献出自己的力量。
(转载请注明作者:Dr.2,愿意与Dr.2交流的请加微信号:1340603421)
返回搜狐,查看更多
责任编辑:





