语音技术
接口描述
实时语音识别接口采用websocket协议的连接方式,边上传音频边获取识别结果。可以将音频流实时识别为文字,也可以上传音频文件进行识别;返回结果包含每句话的开始和结束时间,适用于长句语音输入、音视频字幕、直播质检、会议记录等场景。
WebSocket简介
WebSocket 是基于TCP的全双工协议,即建立连接后通讯双方都可以不断发送数据。
WebSocket 协议由rfc6455定义, 下面介绍常见WebSocket 库的调用流程及参数
一般需要各编程语言的WebSocket库来实现接入。WebSocket库需支持rfc6455描述的协议, 即支持Sec-WebSocket-Version: 13
主要流程
连接 连接成功后发送数据2.1 发送开始参数帧
2.2 实时发送音频数据帧
2.3 库接收识别结果
2.4 发送结束帧 关闭连接
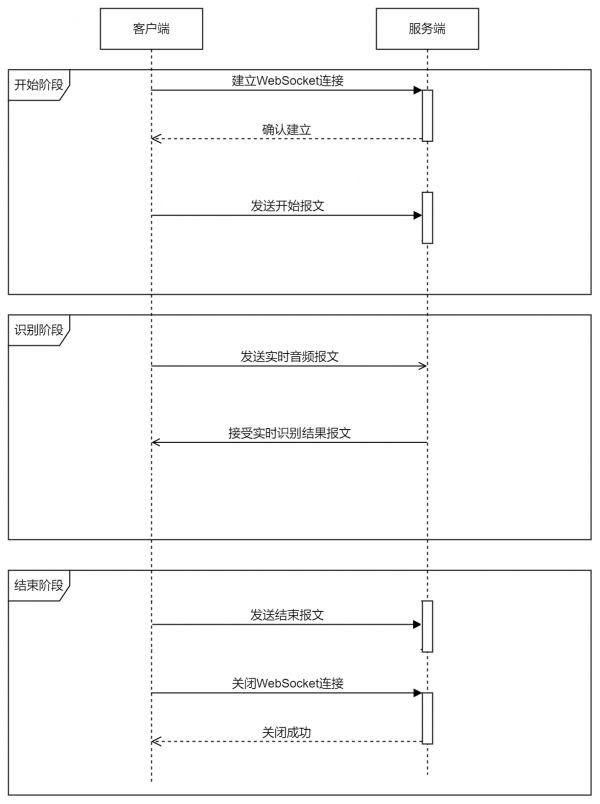 名词解释: 连接: 这里指TCP连接及握手(Opening Handshake) , 一般WebSocket库已经封装,用户不必关心
名词解释: 连接: 这里指TCP连接及握手(Opening Handshake) , 一般WebSocket库已经封装,用户不必关心 发送数据帧:Sending Data Frame, 类似包的概念,指一次发送的内容 。从客户端到服务端。
文本帧:Opcode 0x1 (Text), 实时语音识别api发送的第一个开始参数帧和最后一个结束帧,文本的格式是json 二进制帧:Opcode0x2 (Binary), 实时语音识别api 发送的中间的音频数据帧接收数据帧: Receiving Data Frame, 类似包的概念,指一次发送的内容 。从服务端到客户端。
文本帧:Opcode 0x1 (Text), 识别结果或者报错,文本的格式是json 二进制帧:实时语音识别api 不会收到 关闭连接:Closing Handshake。 百度服务端识别结束后会自行关闭连接,部分WebSocket库需要得知这个事件后手动关闭客户端连接。通常WebSocket库用需要用户自己定义下面的3个回调函数实现自己的业务逻辑。
连接成功后的回调函数: {#通常需要开启一个新线程,以避免阻塞无法接收数据2.1 发送开始参数帧2.2 实时发送音频数据帧2.4 发送结束帧 } 接收数据的回调函数 {2.3 库接收识别结果,自行解析json获得识别结果 } 服务端关闭连接的回调函数 {3. 关闭客户端连接, 部分库可以自动关闭客户端连接。 }
在线调试&示例代码
Demo 目前提供如下demo及演示功能,点击进入下载页面
编程语言 操作系统及版本 使用文件流演示接口基本识别功能 耗时计算 模拟实时音频流 断网补发数据 Java 任意,支持Java 8或以上 √ √ √ Android Android Api Level 15 或以上 √ √ √ Python 任意,支持Python3 √ C++ Linux ,支持C++ 11 以上 √请求说明
连接
连接地址(WebSocket URI):wss://vop.baidu.com/realtime_asr?sn=XXXX-XXXX-XXXX-XXX 参数 sn由用户自定义用于排查日志,建议使用随机字符串如UUID生成。 sn的格式为英文数字及“-” ,长度128个字符内,即[a-zA-Z0-9-]{1, 128}
如果连接成功,一般WebSocket库会发起回调。
发送开始参数帧
注意帧的类型(Opcode)是Text, 使用json序列化
示例:
{ "type": "START", "data": { "appid": 105xxx17, "appkey": "UA4oPSxxxxkGOuFbb6", "dev_pid": 15372, # 识别模型,比如普通话还是英语,是否要加标点等 "lm_id": xxxx, # 自训练平台才有这个参数 "cuid": "cuid-1", # 随便填不影响使用。机器的mac或者其它唯一id,页面上计算UV用。 # 下面是固定参数 "format": "pcm", "sample": 16000 } }
具体参数说明
参数名称 类型 是否必填 说明 type String 必填,固定值 START,开始帧的类型 data Array 必填 具体见下表data参数说明
参数名称 类型 是否必填 说明 appid int 必填 控制台网页上应用的鉴权信息 AppID appkey string 必填 控制台网页上应用的鉴权信息 API Key dev_pid int 必填 识别模型,推荐15372,见下一个表格 lm_id int 可选 填入自训练平台训练上线的模型id,需要和训练的基础模型dev-pid对齐。参考平台模型调用部分的提示。 cuid string 必填 统计UV使用,发起请求设备的唯一id,如服务器的mac地址。随意填写不影响识别结果。长度128个字符内,即[a-zA-Z0-9-_]{1, 128} format string 必填,固定值 pcm , 固定格式 sample int 必填,固定值 16000, 固定采样率开放平台模型(无在线语义功能)
PID 模型 是否有标点及后处理 推荐场景 1537 中文普通话 弱标点(逗号,句号) 手机近场输入 15372 中文普通话 加强标点(逗号、句号、问号、感叹号) 手机近场输入 1737 英语 无标点 手机近场输入 17372 英语 加强标点(逗号、句号、问号) 手机近场输入语音自训练平台模型训练
实时语音识别接口支持在语音自训练平台上训练中文普通话模型 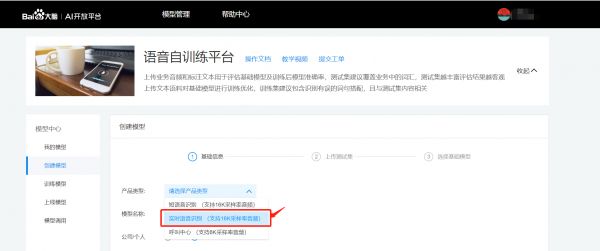
训练后的模型注意必须填写上线模型的模型参数,可在自训练平台的模型调用模块进行查看。
示例 获取专属模型参数pid:1537或15372 modelid:1235, 则调用websocket API时必须填写参数 dev_pid=1537或15372(PID功能见下表);同时lm_id 设置为1235。
PID 模型 是否有标点 备注 1537 中文普通话 无标点 15372 中文普通话 加强标点(逗号、句号、问号、感叹号)发送音频数据帧
这里需要注意,服务端5s没有收到音频数据会断开并报错,发送间隔控制在5s以内
注意帧的类型(Opcode)是Binary
内容是二进制的音频内容。 除最后一个音频数据帧, 每个帧的音频数据长度为20-200ms。 建议最佳160ms一个帧,有限制的也建议80ms。
160ms = 160 (16000 2 /1000) = 5120 bytes
计算方式: 16000采样率: 1s音频 16000采样点 16bits: 一个采样点 16bits = 2 bytes 1s : = 1000ms 即 160ms * 16000 * 2bytes / 1000ms = 5120bytes
实时语音识别api 建议实时发送音频,即每个160ms的帧之后,下一个音频数据帧需要间隔160ms。即:文件,此处需要sleep(160ms) 如果传输过程中网络异常, 需要补断网时的识别结果,发送的音频数据帧之间可以没有间隔。具体见下文“断网补发数据”一节
发送结束帧
注意帧的类型(Opcode)是Text, 使用json序列化
示例:
具体参数说明
参数名称 类型 是否必填 说明 type String 必填,固定值 , 结束帧的类型发送取消帧
取消与结束不同,结束表示音频正常结束,取消表示不再需要识别结果,服务端会迅速关闭连接 示例:
具体参数说明
参数名称 类型 是否必填 说明 type String 必填,固定值 CANCEL 立即取消本次识别发送心跳帧
注意帧的类型(Opcode)是Text, 使用json序列化 正常情况下不需要发这个帧,仅在网络异常的时候,需要补传使用,具体见“断网补发数据”
示例:
具体参数说明
参数名称 类型 是否必填 说明 type String 必填,固定值 HEARTBEAT, 心跳帧的类型返回说明
接收数据帧
注意需要接收的帧类型(Opcode)是Text, 本接口不会返回Binary类型的帧。 text的内容, 使用json序列化
临时及最终识别结果
一段音频由多句话组成,实时识别api会依次返回每句话的临时识别结果和最终识别结果
一句话的临时识别结果示例:
{"err_no":0,"err_msg":"OK","type": "MID_TEXT","result": "北京天气怎","log_id": 45677785,"sn": "399427ce-e999-11e9-94c8-fa163e4e6064_ws_2" }
一句话的最终识别结果:
{"err_no":0,"err_msg":"OK","type":"FIN_TEXT","result":"北京天气怎么样","start_time":53220,"end_time":73340,"err_no":0,"err_msg":"OK","log_id":45677785,"sn":"399427ce-e999-11e9-94c8-fa163e4e6064_ws_2" }
心跳帧(收到后,请忽略)
示例:
与发送的心跳帧不同,这个是接收服务端下发的,5s一次,收到后可以忽略。
服务端报错 如-3005错误码,是针对的是一个句子的,其它句子依旧可以识别,请求是否结束以服务端是否关闭连接为准。 具体错误码含义见文末“错误码“一节
{"err_msg": "asr authentication failed","err_no": -3004,"log_id": 106549729,"result": "","sn": "0d25b5e1-ffa6-11e9-8968-f496349f3917","type": "FIN_TEXT" }
一句话的开始时间及结束时间:识别过程中,百度服务端在每句话的最终识别结果中带有这句话的开始和结束时间。最终识别结果是指"type":"FIN_TEXT",即一句话的最后识别结果,包括这句话的报错结果。
通常一个音频会得到如下的时间信息:
# s1 e1 指第一句话的开始和结束时间start_time,end_time [静音][s1:e1][静音][s2:e2]....[静音][s10:e10][静音] 一句话不能超过60s,否则会被强制切割
参数说明
参数名称 名称 类型 说明 err_no 错误码 int 0 表示正确, 其它错误码见文末 err_msg 错误信息 string err_no!=0时,具体的报错解释。 type 结果类型 string 见下面3行示临时识别结果 ~ ~ MID_TEXT 一句话以及临时识别结果 ~ ~ FIN_TEXT 一句话的最终识别结果或者报错, 是否报错由err_no判断 ~ ~ HEARTBEAT 仅断网补发音频数据需要,见下文“断网补发数据”一节 result 识别结果 string 音频的识别结果 start_time 一句话的开始时间 int,毫秒 一句话的开始时间,临时识别结果MID_TEXT 无此字段 end_time 一句话的结束时间 int,毫秒 一句话的结束时间,临时识别结果MID_TEXT 无此字段 logid 日志id long 日志id,用这个id可以百度服务端定位请求,排查问题 sn 请求sn string 用这个sn可以百度服务端定位请求,排查问题。ws URI里的参数及识别句子的组合断网补发数据
请先看“发送音频数据帧” 和 “接收数据帧” 这2节。
断网补发数据的目的是将一个语音流,在网络不佳的情况下,通过自己的代码逻辑拼接,使得多次请求的结果看上去像一次。
简单来说就是哪里断开,从哪里开始重新发一次请求,“哪里”=最后一次接收的“end_time”。服务端对每个请求独立,需要自行拼接补发数据的请求时间。
如果一个音频的10个句子时间如下:
# s1 e1 指第一句话的开始和结束时间start_time,end_time [静音][s1:e1][静音][s2:e2]...[s7:e7]...[静音][s10:e10][静音]
如果发送过程中,比如在第七句e7之后,网络抖动或者遇见其它错误。但是为了不影响最终的用户体验,期望连续的10个句子的识别结果。
此时,可以发起一个新的请求,从e7开始发数据,在,语音数据帧之间不需要sleep。
如果超过5s没有发送音频数据给服务端,服务端会下发报错并结束连接,建议至少2s 发送一次。
完整流程如下
开始一次请求,正常发送音频数据,并缓存音频数据, 接收到数据帧, 保存end_time 如果此时断网,读取最后一次的end_time如7000ms 开始一次新请求, 从缓存的音频数据中找到7000ms(224000bytes)以后的数据,发送给服务端。每个帧160ms的音频数据,补数据时,每个帧之间不需要间隔sleep。 一直追上实时音频数据,开始实时发送 新请求的start_time和end_time可以加上7000ms,然后展示给用户 如果补发数据过大,新请求过快结束,在新请求结束时,需要补type=HEARTBEAT心跳帧,建议2-3s发一次,避免5s服务端读超时。 如果再次断网流程依旧相关知识
语音识别抑郁症的关键技术研究
智能语音识别技术:赋能人工智能应用新篇章
电销机器人=AI人工智能+语音识别技术+语音知识库+话术逻辑+智能学习
语音识别技术在手机心理健康软件中的应用
言语治疗技术
语音识别
什么是智能语音服务(智能语音服务介绍)
ai语音识别声音防沉迷
【基本建成】言语治疗技术
言语听觉康复技术专业介绍
网址: 语音技术 https://www.trfsz.com/newsview681642.html
推荐资讯




- 1从出汗看健康 出汗透露你的健 3976
- 2早上怎么喝水最健康? 3750
- 3习惯造就健康 影响健康的习惯 3387
- 4五大原因危害女性健康 如何保 3291
- 5连花清瘟、布洛芬等多款感冒药 3010
- 6补肾吃什么 补肾最佳食物推荐 2570
- 7男子喝水喉咙里像放了刀子一样 2514
- 810人混检核酸几天出结果?1 2270
- 9第二轮新冠疫情要来了?疾控中 2263
- 10转阴多久没有传染性?满足四个 2210

